
안녕하세요 ~ 린내입니다!
저번 게시글에선 복합키를 사용한 엔티티의 연관관계 조회 이슈까지 알아보았습니다.
부모엔티티와 자식 엔티티를 각각 insert 하고나서, 그래프 탐색을 통해 조회를 하려고 시도했는데,
select문이 나가지 않거나 심지어 select문이 나갔는데도 조회결과가 없는 상황이 발생하였습니다.

왜 그런 것일까요?
저는 이 사항을 해결하기 위해 하이버네이트 영속성 컨텍스트와 1차 캐시에 대해 좀 더 이해할 필요가 있었습니다.
영속성 컨텍스트 및 1차 캐시
1차 캐시
- 1차 캐시는 영속성 컨텍스트에 위치한 메모리 공간
엔티티 저장 방식
- 영속성 컨텍스트에 엔티티 인스턴스가 보관되기 위해선 반드시 식별자 값이 필요합니다..
- 아이덴티티, 시퀀스 PK전략에 따라, insert가 플러시 되는 시점이 다른 이유가 여기에 있습니다.
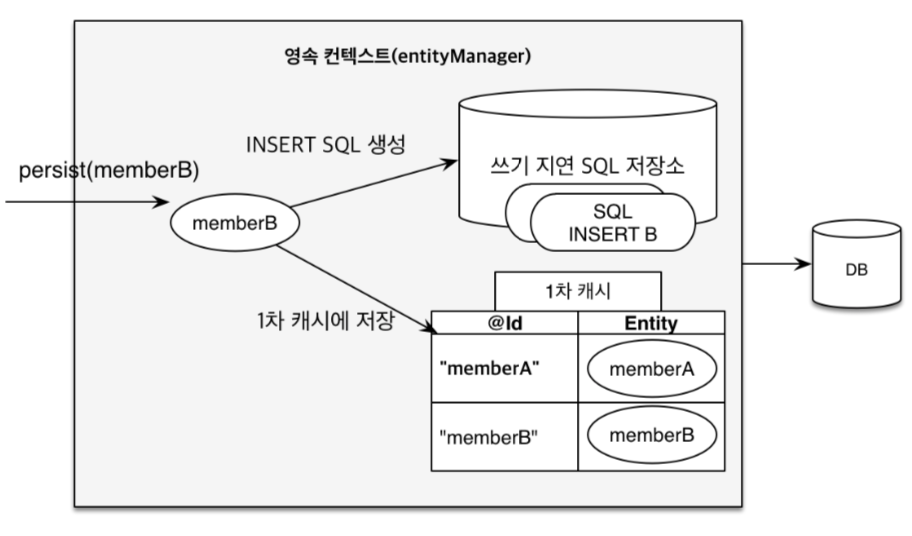
- save() 시 (persist() 시) pk가 존재하면 1차 캐시에 보관하였다가, flush가 발생하면 insertDB로 전달됩니다.
- save() (persist)시점에 pk값이 없으면 즉시 insert 문이 DB로 전달됩니다.
- 엔티티 인스턴스가 영속성 컨텍스트 내부의 Map 형태로 1차 캐시에 보관됨
- Map의 키는 @id로 매핑한 식별자값, 값은 엔티티 인스턴스!!
조회 시
- 엔티티매니저의 find() 메소드가 호출되면 하이버네이트는 해당 엔티티를 먼저 1차 캐시에서 찾고, 없으면 DB를 조회한다.
- 1차 캐시에 없는 것을 확인하고 DB 조회 후, 엔티티를 생성하여 1차 캐시에 저장한다..
- 1차 캐시는 영속성 컨텍스트 내부에 위치함
- 일반 트랜잭션 하나당 연속성 컨텍스트는 하나 존재
- 따라서 트랜잭션 하나당 일차 캐시도 하나 존재하게 된다
- 아래의 예시 코드 같은 경우, 1차 캐시가 존재하지 않는 것이 아니라, 각각의 트랜잭션 마다 각각의 독립된 영속성 컨텍스트 및 1차 캐시가 존재한 것으로 이해할 수 있다.
- cf) 지연조회의 경우, 영속성 컨텍스트 내에서 프록시 접근 가능하므로 example2() 같이 트랜잭션으로 묶이지 않았다면 요청 결과에 대한 연관관계 지연조회는 불가능하다! → 조회해오자마자 영속성 컨텍스트 및 1차 캐시가 클리어 되는 것이므로…
-
@Transactional public void example1(){ Person person1 = personJpaRepository.findById(3L).get(); // select 쿼리 생성 및 fetch Person person2 = personJpaRepository.findById(3L).get(); // select 문 생성 X -> DB에서 가져온 것이 아니라, 1차 캐시에서 가져옴 // -> PK를 키로 인식하여 1차캐시에서 조회해온다. } //@Transactional 트랜잭션 어노테이션을 지정하지 않으면 모든 db요청 당 하나의 트랜잭션이 생기는 것! public void example2(){ Person person1 = personJpaRepository.findById(3L).get(); // select 쿼리 생성 및 fetch -> 트랜잭션 1 Person person2 = personJpaRepository.findById(3L).get(); // select 쿼리 생성 및 fetch -> 트랜잭션 2 // 하나의 트랜잭션 안에서 작동되지 않고 있으므로 1차 캐시가 각각 생성되어 쿼리생성과 fetch가 각각 일어난다! } - 따라서 1차 캐시의 경우 각각의 트랜잭션 내에서 PK를 통한 동등 비교가 이루어짐을 알수가 있다!
저장 시

- 영속성 컨텍스트는 1차 캐시에 엔티티를 저장하면서 동시에 등록 쿼리를 만들어 쓰기지연저장소에 보관함.
- 트랜잭션을 커밋하면 엔티티 매니저는 우선 영속성 컨텍스트를 플러시한다
- JPQL 쿼리를 호출해도 flush가 일어납니다..!
- 플러시는 영속성 컨텍스트의 변경 내용을 DB에 동기화 하는 작업인데 이때 엔티티 정보들을 DB에 반영하는 것으로 이해할 수 있다..
이렇게 영속성 컨텍스트와 1차 캐시에 대한 이론을 정리하고 기존 코드로 되돌아가 봅니다..
@Transactional
public void postEmployee(EmployeeDto employeeDto){
// 0. 엔티티 저장
Employee saved = employeeRepository.save(new Employee(employeeDto.getNickName(), employeeDto.getName()));
employeeDetailRepository.save(new EmployeeDetail(saved.getNickName(), saved.getName())); // 1차 캐시 저장됨
// 논리적으로는 연관관계가 설정된 것이 맞지 않을까? JPA가 무엇인가를 해주지 않았을까..?
// 1. 저장한 엔티티로 연관관계 조회
int size = saved.getEmployeeDetailList().size();// select문 안나감 !
System.out.println(size); //-> PK 비교 후 1차 캐시에 있다고 판단 -> 위의 엔티티의 list 필드는 size() 0이 맞다..
// 2. JPA findById()로 엔티티 조회 후, 연관관계 조회
Employee found = employeeRepository.findById(new EmployeeId(saved.getNickName(), saved.getName())).orElseThrow();
size = found.getEmployeeDetailList().size(); // 위의 find()메소드로도 select문 안나감 !
System.out.println(size); // 먼저 PK 값으로 1차캐시를 조회하는데, 같은 PK 값이 존재하므로 select가 flush되지 않음!!
// 3. querydsl로 엔티티 조회 후, 연관관계 조회
Employee foundByQuerydsl = employeeQueryRepository.findById(saved.getNickName(), saved.getName()).orElseThrow();
size = foundByQuerydsl.getEmployeeDetailList().size(); // 그렇다면 이 경우는 select가 flush 되었는데 왜???
System.out.println(size);
}- 1번 사항과 2번 사항은 지난 게시물에서 알아보았습니다.
- 엔티티가 1차캐시에 저장되는 시점에 해당 인스턴스의 참조 주소값의 존재하는 연관관계 리스트는 길이가 0이 맞습니다.
- insert문이 DB에 전달되어도, 혹은 쓰기지연 저장소에만 있어도 결과는 같습니다.
- 1차 캐시에 저장되는 순간 엔티티 인스턴스의 리스트 길이는 0이 맞기 때문입니다!
- 그런데 3번 사항에서는 ..? select 문이 전달되었는데요…??
- 마지막 경우에 대해 설명하려면 querydsl과 이의 기반 기술인 JPQL에 대한 이해가 필요합니다.
- QueryDsl은 기본적으로 "JPQL을 java코드로 쓸 수 있게 해주는" JPQL 빌더입니다.
- JPQL을 호출하게 되면 flush가 즉시 일어나게 됩니다.
- 쓰기지연저장소에 저장해둔 insert 및 update 쿼리가 flush 됩니다.
- 또한 JPQL을 이용해 select문을 실행하면 1차 캐시를 건너뛰고 바로 DB에게 select문을 전달합니다.
- 그러나 조회해온 결과를 가지고 1차 캐시와 비교를 합니다!
- 조회해온 결과가 1차 캐시에 없다면 1차 캐시에 결과 엔티티를 저장합니다.
- 조회해온 결과가 1차 캐시에 있다면 DB 조회 결과를 버립니다..! (충격..)
- 정리해보자면
- querydsl의 기반기술은 jpql입니다.
- 따라서 querydsl로 select를 할 경우 먼저 1차 캐시를 건너뛰고 select문을 DB로 전달합니다.
- 하지만, DB 결과값은 1차 캐시에 영향을 받습니다!
- 위의 경우, 이미 1차 캐시에 동일한 PK에 해당하는 엔티티 인스턴스가 있으므로 querydsl의 DB 결과 조회값을 버립니다..!!!
- 따라서 외의 예시코드의 모든 조회 결과, 연관관계 리스트의 길이는 0이 맞습니다..
- 그렇다면 연관관계 조회, 어떻게 하는 것일까요?
- 제가 위에서 뻘 짓을 많이 했지만….
- 정답은 쉽습니다. 책이든 인강에서 많이 보았던 연관관계 편의 set메소드를 호출해주면 됩니다.
- 식별관계 복합키를 사용하면, 키만으로도 논리적인 연관관계를 표현할 수가 있어서 연관관계 설정이 되었다고 착각하기 쉽습니다..
- 하지만 1차 캐시의 경우 엔티티 인스턴스 그 자체로만 연관관계를 알수가 있으므로 꼭 인스턴스 안에서의 연관관계 편의 메소드를 호출해주어야 합니다!
- (애초에 식별관계 복합키를 사용하지 않으면 애초에 set()메소드 없이 연관관계를 설정할 수 없습니다..)
- 식별관계 복합키는 외래키를 직접 제어하므로 set()메소드 사용하지 않더라도, 엔티티가 1차캐시에 저장되어 있지 않은 경우에 대해 연관관계 조회 가능 (다른 트랜잭션으로 조회한다면)
// 연관관계 편의 메소드
public void setTeam(Team team) {
if (this.team != null) {
this.team.getMembers().remove(this);
}
this.team = team;
team.getMembers().add(this);
}
참고자료)
https://insanelysimple.tistory.com/406
https://www.youtube.com/watch?v=wBK2THyXmE4&list=LL&index=13
https://velog.io/@cws0718/Spring-JPA-QueryDsl%EC%9D%B4%EB%a%80
김영한, 자바 orm 표준 jpa 프로그래밍
'백엔드 > JPA' 카테고리의 다른 글
| JPA 영속성 전이 정리 - (영속성 컨텍스트 및 엔티티 생명주기, 영속성 전이 옵션과 insertable=false, updatable=false 설정) (3) | 2024.04.15 |
|---|---|
| JPA 양방향 연관관계 매핑 시, 순수 객체와 엔티티 작동 차이점 (0) | 2024.03.16 |
| 복합키 JPA 사용 시 연관관계 및 1차 캐시 주의 사항 (2) | 2024.01.06 |
안녕하세요 ~ 린내입니다!
저번 게시글에선 복합키를 사용한 엔티티의 연관관계 조회 이슈까지 알아보았습니다.
부모엔티티와 자식 엔티티를 각각 insert 하고나서, 그래프 탐색을 통해 조회를 하려고 시도했는데,
select문이 나가지 않거나 심지어 select문이 나갔는데도 조회결과가 없는 상황이 발생하였습니다.
왜 그런 것일까요?
저는 이 사항을 해결하기 위해 하이버네이트 영속성 컨텍스트와 1차 캐시에 대해 좀 더 이해할 필요가 있었습니다.
영속성 컨텍스트 및 1차 캐시
1차 캐시
- 1차 캐시는 영속성 컨텍스트에 위치한 메모리 공간
엔티티 저장 방식
- 영속성 컨텍스트에 엔티티 인스턴스가 보관되기 위해선 반드시 식별자 값이 필요합니다..
- 아이덴티티, 시퀀스 PK전략에 따라, insert가 플러시 되는 시점이 다른 이유가 여기에 있습니다.
- save() 시 (persist() 시) pk가 존재하면 1차 캐시에 보관하였다가, flush가 발생하면 insertDB로 전달됩니다.
- save() (persist)시점에 pk값이 없으면 즉시 insert 문이 DB로 전달됩니다.
- 엔티티 인스턴스가 영속성 컨텍스트 내부의 Map 형태로 1차 캐시에 보관됨
- Map의 키는 @id로 매핑한 식별자값, 값은 엔티티 인스턴스!!
조회 시
- 엔티티매니저의 find() 메소드가 호출되면 하이버네이트는 해당 엔티티를 먼저 1차 캐시에서 찾고, 없으면 DB를 조회한다.
- 1차 캐시에 없는 것을 확인하고 DB 조회 후, 엔티티를 생성하여 1차 캐시에 저장한다..
- 1차 캐시는 영속성 컨텍스트 내부에 위치함
- 일반 트랜잭션 하나당 연속성 컨텍스트는 하나 존재
- 따라서 트랜잭션 하나당 일차 캐시도 하나 존재하게 된다
- 아래의 예시 코드 같은 경우, 1차 캐시가 존재하지 않는 것이 아니라, 각각의 트랜잭션 마다 각각의 독립된 영속성 컨텍스트 및 1차 캐시가 존재한 것으로 이해할 수 있다.
- cf) 지연조회의 경우, 영속성 컨텍스트 내에서 프록시 접근 가능하므로 example2() 같이 트랜잭션으로 묶이지 않았다면 요청 결과에 대한 연관관계 지연조회는 불가능하다! → 조회해오자마자 영속성 컨텍스트 및 1차 캐시가 클리어 되는 것이므로…
-
@Transactional public void example1(){ Person person1 = personJpaRepository.findById(3L).get(); // select 쿼리 생성 및 fetch Person person2 = personJpaRepository.findById(3L).get(); // select 문 생성 X -> DB에서 가져온 것이 아니라, 1차 캐시에서 가져옴 // -> PK를 키로 인식하여 1차캐시에서 조회해온다. } //@Transactional 트랜잭션 어노테이션을 지정하지 않으면 모든 db요청 당 하나의 트랜잭션이 생기는 것! public void example2(){ Person person1 = personJpaRepository.findById(3L).get(); // select 쿼리 생성 및 fetch -> 트랜잭션 1 Person person2 = personJpaRepository.findById(3L).get(); // select 쿼리 생성 및 fetch -> 트랜잭션 2 // 하나의 트랜잭션 안에서 작동되지 않고 있으므로 1차 캐시가 각각 생성되어 쿼리생성과 fetch가 각각 일어난다! } - 따라서 1차 캐시의 경우 각각의 트랜잭션 내에서 PK를 통한 동등 비교가 이루어짐을 알수가 있다!
저장 시
- 영속성 컨텍스트는 1차 캐시에 엔티티를 저장하면서 동시에 등록 쿼리를 만들어 쓰기지연저장소에 보관함.
- 트랜잭션을 커밋하면 엔티티 매니저는 우선 영속성 컨텍스트를 플러시한다
- JPQL 쿼리를 호출해도 flush가 일어납니다..!
- 플러시는 영속성 컨텍스트의 변경 내용을 DB에 동기화 하는 작업인데 이때 엔티티 정보들을 DB에 반영하는 것으로 이해할 수 있다..
이렇게 영속성 컨텍스트와 1차 캐시에 대한 이론을 정리하고 기존 코드로 되돌아가 봅니다..
@Transactional
public void postEmployee(EmployeeDto employeeDto){
// 0. 엔티티 저장
Employee saved = employeeRepository.save(new Employee(employeeDto.getNickName(), employeeDto.getName()));
employeeDetailRepository.save(new EmployeeDetail(saved.getNickName(), saved.getName())); // 1차 캐시 저장됨
// 논리적으로는 연관관계가 설정된 것이 맞지 않을까? JPA가 무엇인가를 해주지 않았을까..?
// 1. 저장한 엔티티로 연관관계 조회
int size = saved.getEmployeeDetailList().size();// select문 안나감 !
System.out.println(size); //-> PK 비교 후 1차 캐시에 있다고 판단 -> 위의 엔티티의 list 필드는 size() 0이 맞다..
// 2. JPA findById()로 엔티티 조회 후, 연관관계 조회
Employee found = employeeRepository.findById(new EmployeeId(saved.getNickName(), saved.getName())).orElseThrow();
size = found.getEmployeeDetailList().size(); // 위의 find()메소드로도 select문 안나감 !
System.out.println(size); // 먼저 PK 값으로 1차캐시를 조회하는데, 같은 PK 값이 존재하므로 select가 flush되지 않음!!
// 3. querydsl로 엔티티 조회 후, 연관관계 조회
Employee foundByQuerydsl = employeeQueryRepository.findById(saved.getNickName(), saved.getName()).orElseThrow();
size = foundByQuerydsl.getEmployeeDetailList().size(); // 그렇다면 이 경우는 select가 flush 되었는데 왜???
System.out.println(size);
}- 1번 사항과 2번 사항은 지난 게시물에서 알아보았습니다.
- 엔티티가 1차캐시에 저장되는 시점에 해당 인스턴스의 참조 주소값의 존재하는 연관관계 리스트는 길이가 0이 맞습니다.
- insert문이 DB에 전달되어도, 혹은 쓰기지연 저장소에만 있어도 결과는 같습니다.
- 1차 캐시에 저장되는 순간 엔티티 인스턴스의 리스트 길이는 0이 맞기 때문입니다!
- 그런데 3번 사항에서는 ..? select 문이 전달되었는데요…??
- 마지막 경우에 대해 설명하려면 querydsl과 이의 기반 기술인 JPQL에 대한 이해가 필요합니다.
- QueryDsl은 기본적으로 "JPQL을 java코드로 쓸 수 있게 해주는" JPQL 빌더입니다.
- JPQL을 호출하게 되면 flush가 즉시 일어나게 됩니다.
- 쓰기지연저장소에 저장해둔 insert 및 update 쿼리가 flush 됩니다.
- 또한 JPQL을 이용해 select문을 실행하면 1차 캐시를 건너뛰고 바로 DB에게 select문을 전달합니다.
- 그러나 조회해온 결과를 가지고 1차 캐시와 비교를 합니다!
- 조회해온 결과가 1차 캐시에 없다면 1차 캐시에 결과 엔티티를 저장합니다.
- 조회해온 결과가 1차 캐시에 있다면 DB 조회 결과를 버립니다..! (충격..)
- 정리해보자면
- querydsl의 기반기술은 jpql입니다.
- 따라서 querydsl로 select를 할 경우 먼저 1차 캐시를 건너뛰고 select문을 DB로 전달합니다.
- 하지만, DB 결과값은 1차 캐시에 영향을 받습니다!
- 위의 경우, 이미 1차 캐시에 동일한 PK에 해당하는 엔티티 인스턴스가 있으므로 querydsl의 DB 결과 조회값을 버립니다..!!!
- 따라서 외의 예시코드의 모든 조회 결과, 연관관계 리스트의 길이는 0이 맞습니다..
- 그렇다면 연관관계 조회, 어떻게 하는 것일까요?
- 제가 위에서 뻘 짓을 많이 했지만….
- 정답은 쉽습니다. 책이든 인강에서 많이 보았던 연관관계 편의 set메소드를 호출해주면 됩니다.
- 식별관계 복합키를 사용하면, 키만으로도 논리적인 연관관계를 표현할 수가 있어서 연관관계 설정이 되었다고 착각하기 쉽습니다..
- 하지만 1차 캐시의 경우 엔티티 인스턴스 그 자체로만 연관관계를 알수가 있으므로 꼭 인스턴스 안에서의 연관관계 편의 메소드를 호출해주어야 합니다!
- (애초에 식별관계 복합키를 사용하지 않으면 애초에 set()메소드 없이 연관관계를 설정할 수 없습니다..)
- 식별관계 복합키는 외래키를 직접 제어하므로 set()메소드 사용하지 않더라도, 엔티티가 1차캐시에 저장되어 있지 않은 경우에 대해 연관관계 조회 가능 (다른 트랜잭션으로 조회한다면)
// 연관관계 편의 메소드
public void setTeam(Team team) {
if (this.team != null) {
this.team.getMembers().remove(this);
}
this.team = team;
team.getMembers().add(this);
}
참고자료)
https://insanelysimple.tistory.com/406
https://www.youtube.com/watch?v=wBK2THyXmE4&list=LL&index=13
https://velog.io/@cws0718/Spring-JPA-QueryDsl%EC%9D%B4%EB%a%80
김영한, 자바 orm 표준 jpa 프로그래밍
'백엔드 > JPA' 카테고리의 다른 글
| JPA 영속성 전이 정리 - (영속성 컨텍스트 및 엔티티 생명주기, 영속성 전이 옵션과 insertable=false, updatable=false 설정) (3) | 2024.04.15 |
|---|---|
| JPA 양방향 연관관계 매핑 시, 순수 객체와 엔티티 작동 차이점 (0) | 2024.03.16 |
| 복합키 JPA 사용 시 연관관계 및 1차 캐시 주의 사항 (2) | 2024.01.06 |